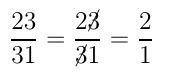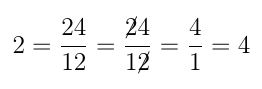In this blog series, I am exploring a few of my favourite algorithms in mathematics.
Last week, we looked at an algorithm that allowed us to calculate the greatest common divisor of two numbers using halving and subtraction. This week, I want to dive into the idea of divisibility rules.
Some numbers have easy divisibility rules. For example, a number is divisible by 2 if it ends in a 0, 2, 4, 6, or 8. It doesn’t take much mental energy to confirm that 
But what about 3? Is
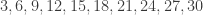
This list is not good news. Notice that these numbers end in every possible digit! So is 
15 is divisible by 3 and ends in a 5. But 25 also ends in a 5 and clearly 25 is not divisible by 3. Ending in a 5 is not enough to determine divisibility by 3. So all we can say is maybe, maybe
This illustrates a very crucial fact: to determine divisibility by 3, we need to look beyond the last digit of the number. Indeed, in the divisibility rule for 3, all the digits in the number will play a role.
The first step is to forget about the place value of each of these digits and simply treat them as individual numbers. Next, we add up all these numbers. For

Now we ask a surprising question, is this new number divisible by 3? For sure! 24 is on our list of numbers divisible by 3. So the rule says, since this new number is divisible by 3, the original number is divisible by 3. Done.
Don’t believe me? Calculate 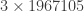
Let’s try a smaller number. Clearly 
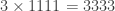

Since 12 is divisible by 3,
We can even apply this rule multiple times. Consider the gigantic number 
First, we add all the digits:

Now 54 is not on our list. We could try some mental math to determine if 54 is or is not divisible by 3, but instead, we can just add the digits again!
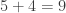
9 is on our list and we are done,
To see why this works, consider 

This means
Now let’s unpack what we did. The first 2 actually stands for 2 groups of 1000, the 7 stands for 7 groups of 100, the 8 stands for 8 groups of 10, and the last 4 stands for 4. We could write this as:
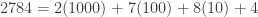
Next, we break off a 1 from each of these powers of 10. This give us:

Finally, we can use the distributive property and get:
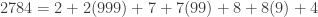
Now 
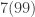

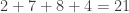
This is just adding up all the digits, exactly what we were doing! In essence, by only using the digit and not the place value, we are disregarding either a 9, or a 99, or a 999. But these numbers are already divisible by 3 and so disregarding them is totally fine.
As a fun extension, this rule also works for divisibility by 9. So, our first number
I love both of these divisibility rules because they employ such simple mathematical operations. Trying to do long division on a number like
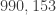
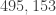
 , this means we have:
, this means we have:
 .
. , and this gives us:
, and this gives us: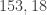
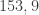 (Halve it)
(Halve it)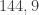 (Subtract em)
(Subtract em) (Halve it)
(Halve it)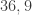 (Halve it)
(Halve it) (Halve it)
(Halve it) (Done!)
(Done!)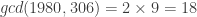
 . You could your hand at long multiplication to find the answer. However, I want to show you a more interesting method, an algorithm you probably never learned in school.
. You could your hand at long multiplication to find the answer. However, I want to show you a more interesting method, an algorithm you probably never learned in school. which is the correct answer to:
which is the correct answer to:  . This allows us find precisely 29 groups of 31, add them together, and get our total of 899.
. This allows us find precisely 29 groups of 31, add them together, and get our total of 899. . You can use the same table, and I bet you will get 589.
. You can use the same table, and I bet you will get 589. ? There seems to be no way to get to 35 using only the numbers in the left column…
? There seems to be no way to get to 35 using only the numbers in the left column…
 .
.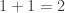 . This is a correct mathematical statement. Of course, one and one gives two.
. This is a correct mathematical statement. Of course, one and one gives two. . This is also a correct mathematical statement. Two groups of three will produce a total of six.
. This is also a correct mathematical statement. Two groups of three will produce a total of six.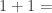 it will give you the number
it will give you the number  . Then, you can go ahead and type
. Then, you can go ahead and type 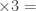 and the calculator will happily give you the number
and the calculator will happily give you the number  .
.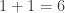
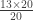

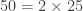 , we can cancel the 25 on the top and bottom to leave us with the much simpler expression:
, we can cancel the 25 on the top and bottom to leave us with the much simpler expression: