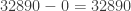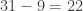Today I want to investigate a mathematical game called Juniper Green. To play Juniper Green, you first begin with a grid of the numbers 1 through 40. Each player takes turns removing numbers from the grid. But they can’t pick just any number. Each number chosen must either be a factor or multiple of the previous player’s choice. If a player is unable to choose a number, then the game is over and they lose. Oh, and the person who goes first must pick an even number to start.
Let’s play. Suppose the first player chooses 20. The second player can now choose either a factor (1, 2, 5, 10) or a multiple (40):

Say they choose 2. Now the next player can choose either a factor (1) or a multiple (4, 6, 8, 10, etc.)

As the game progresses, it will become clear that choosing the number 1 is a very bad move. If someone takes the number 1, then their opponent can take any other number:
And there are some special numbers, prime numbers, that are particularly useful in Juniper Green. If a player takes 37, the game is over. There are no multiples of 37 in sight, the only factor of 37 is 1, and that number is gone.
If you play a few rounds of Juniper Green, it can feel pretty random. Sometimes you win, and sometimes you lose. Sure, there is some strategy, like not picking the number 1, but it also feels like luck plays a major role in this game.
Believe it or not, the first player has a winning strategy. Consider the following sequence of moves, I will be player one and you will be player two. I start with 22. Next, there are only 2 possible options, either 2 or 11, and we will examine them individually.
Suppose you take 11. Next, I take 33. Because 33 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 3, so you must take 3.
Next, I take 21. Because 21 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 7, so you must take 7.
Next, I take 35. Because 35 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 5, so you must take 5.
Next, I take 25. Because 25 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 1, so you must take the number 1 and you lose.
To complete my victory, I take the prime number 37 and I win.
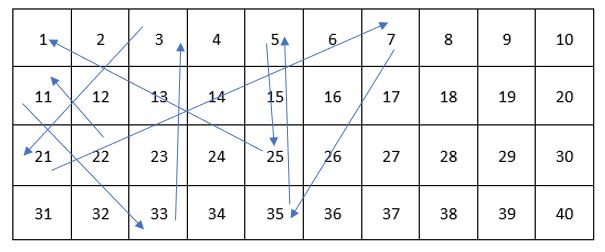
Now consider the other option, suppose you take the 2. Next, I take 26. Because 26 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 13, so you must take 13.
Next, I take 39. Because 39 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 3, so you must take 3.
Next, I take 21. Because 21 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 7, so you must take 7.
Next, I take 35. Because 35 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 5, so you must take 5.
Next, I take 25. Because 25 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 1, so you must take the number 1 and you lose.
To complete my victory, I take the prime number 37 and I win.
In either case, you lose. And your moves are tightly constrained. At each step, you only have one number you can pick. When you play against someone who knows this strategy, your doom feels inevitable. They have outmaneuvered you at every turn.
However, you can still have fun with this game, you just need to add more numbers! If you allow numbers 1 to 100, this strategy breaks down. If I start with 22, there are many possible moves other than 2 and 11. You could take a multiple, like 44, 66, or even 88! I wonder, is there a way to win at this new, expanded game of Juniper Green? Give it a try!
Alright, hopefully you gave the 1 to 100 version of Juniper Green a try. If you did, you might have realized that there is also a winning sequence in this version.
I start with 58. Next, there are only 2 possible options, either 2 or 29, and we will examine them individually.
Suppose you take 2. Next, I take 62. Because 62 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 31, so you must take 31.
I take 93, you must take 3.
I take 57, you must take 19.
I take 95, you must take 5.
I take 65, you must take 13.
I take 91, you must take 7.
I take 77, you must take 11.
I take 55, and since the 5 has already been removed, you must take the 1 and you lose.
To complete my victory, I can take the prime number 97 and I win.
Suppose you take 29. Next, I take 87. Because 87 is a large number, there are no multiples for you to take, you must take a factor. However, the only factor left is 3, so you must take 3. From here, the moves are the same as above.
I take 93, you must take 3.
I take 57, you must take 19.
I take 95, you must take 5.
I take 65, you must take 13.
I take 91, you must take 7.
I take 77, you must take 11.
I take 55, and since the 5 has already been removed, you must take the 1 and you lose.
To complete my victory, I can take the prime number 97 and I win.
The key to my victory is that I always picked a number too large for you to take multiples. Additionally, the number I picked only had one prime factor left on the board. By picking numbers in this way, I left you with no options. Your moves were always forced, and I was able to keep you dancing around the board until you had to take the number 1. Does this strategy work for the numbers 1 to 1000? What about 1 to 10000? Leave your answer in the comments below.












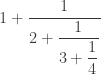
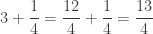
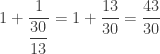
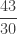
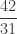 , how could we find the continued fraction?
, how could we find the continued fraction?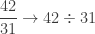 , then use division to determine the remainder (in this case, the remainder is 11)
, then use division to determine the remainder (in this case, the remainder is 11)
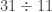 :
:
 :
: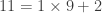
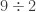 :
:
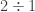 :
: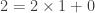
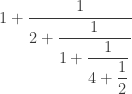
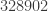 divisible by 7?
divisible by 7?
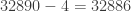
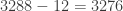 pop, double-subtract
pop, double-subtract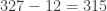 pop, double-subtract
pop, double-subtract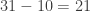 pop, double-subtract
pop, double-subtract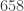 .
.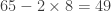
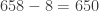
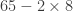 is actually
is actually 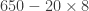 . Although it seemed like we doubled the 8, to keep the place value correct, we actually multiplied the 8 by 20. Doing both steps at once looks like this:
. Although it seemed like we doubled the 8, to keep the place value correct, we actually multiplied the 8 by 20. Doing both steps at once looks like this: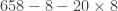
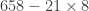
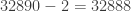 pop, subtract
pop, subtract pop, subtract
pop, subtract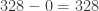 pop, subtract
pop, subtract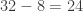 pop, subtract
pop, subtract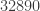 …
…